
西暦2054年、ワシントンD.C.——。この街では、凶悪犯罪が「発生する前」に抑止される。
映画『マイノリティ・リポート』が描く社会は、犯罪予防局(PreCrime)が誇る「犯罪予測システム」の稼働により完全なる治安を現実の物としたディストピアの完成形だ。、街の殺人発生率は驚異の「0%」を達成している。
劇中において、この圧倒的な治安維持を可能にしているのは、未来の殺人を予知する能力を持った3人の予知能力者「プリコグ」だ。彼らが脳内に描く断片的なビジョンをシステムが統合・解析し、犯行日時、被害者、そして加害者の名前を特定する。
SF映画特有の純粋な「ファンタジー(超能力)」の産物ではあるものの、しかし。
現代のAIエンジニア、そしてデータサイエンティストの視点からこのシステムをリファクタリング(再解釈)したとき、その姿は全く別のものとして浮かび上がってくる。
エンジニア的視点での再定義: 3人のプリコグは、言い換えればそれぞれ異なる特徴量を学習した「超高性能な3つの独立した予測モデル」であり、犯罪予測システムとは、それらの出力を束ねる「アンサンブル学習を実装した高度なデータパイプライン」そのものと言える。
この犯罪予測システムを「ファンタジー」として片付けるのではなく、現代の最先端AI技術を総動員した場合、「あのシステムをどこまで現実世界に再現・実装できるか」という可能性にガチで迫っていく。
予測モデルの構築からデータの統合プロセスまで、現代のデータサイエンスという武器を使って、あのシステムを徹底的にリバースエンジニアリングしてみよう。
【アンサンブル学習としてのプリコグ:なぜ「3人」のモデルが必要なのか】
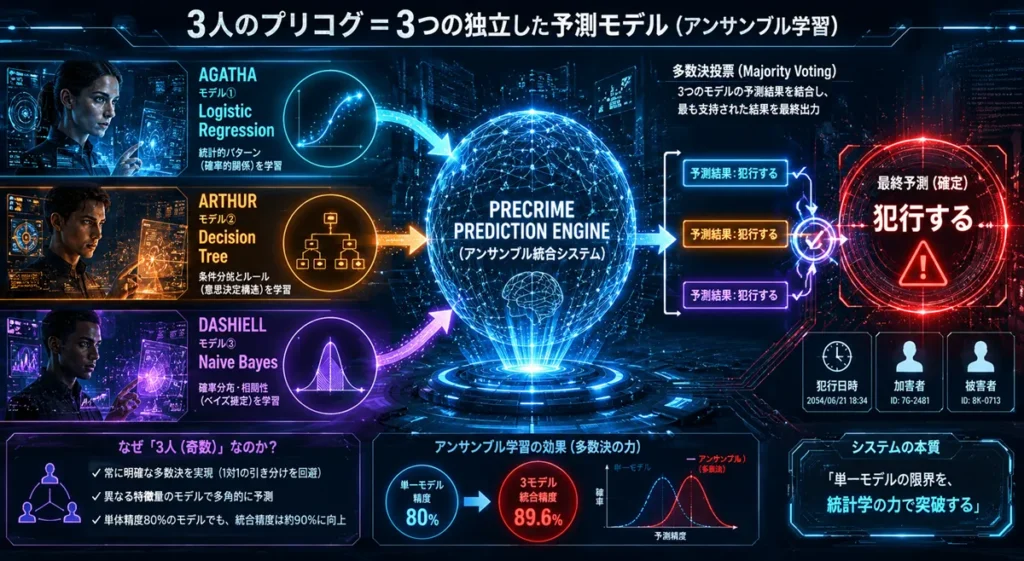
犯罪予測システムには、3人のプリコグ(アガサ、アーサー、ダシール)が組み込まれている。システムは彼らが見た未来のビジョンを統合し、最終的な予測(犯行予知)を出力する。
これを現代のデータサイエンスの視点で翻訳すると、完全に「アンサンブル学習(Ensemble Learning)」のアーキテクチャそのものになる。
アンサンブル学習とは、1つの強力なAIモデルに頼るのではなく、複数の独立したモデルの予測結果を組み合わせることで、全体の予測精度を向上させ、過学習(特定のデータに偏ること)を防ぐ機械学習の王道アプローチだ。
劇中のプレクリム・システムが採用しているのは、その中でも最も直感的で強力な「多数決投票(Majority Voting)」アルゴリズム。
では、なぜ「3人(3つのモデル)」でなければならなかったのか? 統計学の観点から、これには極めて合理的な裏付けがある。
from sklearn.ensemble import VotingClassifier
from sklearn.linear_model import LogisticRegression
from sklearn.naive_bayes import GaussianNB
from sklearn.tree import DecisionTreeClassifier
# 3人のプリコグ(3つの異なる特徴を持つ予測モデル)をインスタンス化
model_agatha = LogisticRegression() # モデル①: ロジスティック回帰
model_arthur = DecisionTreeClassifier() # モデル②: 決定木
model_dashiell = GaussianNB() # モデル③: ナイーブベイズ
# 3つのモデルを束ねる「多数決システム(VotingClassifier)」を構築
precrime_system = VotingClassifier(
estimators=[
('agatha', model_agatha),
('arthur', model_arthur),
('dashiell', model_dashiell)
],
voting='hard' # 'hard'に設定することで、ガチの「多数決(マジョリティ・ボース)」になる
)
# あとは通常のモデルと同じように fit(X, y) で学習させれば、自動で多数決ロジックが走る1. 奇数(3以上)であることの論理的必然性
多数決による決定(バイナリ分類)を行うシステムにおいて、偶数(2や4)のモデルを採用するのは設計上の悪手(バグ)になり得る。予測結果が「1対1」や「2対2」で割れた際、システムがデッドロックを起こして意思決定ができなくなるからだ。
そのため、常に明確な「多数派(マジョリティ)」の意思決定を下すための最小の奇数構成として、「3」という数字はシステム工学的に完璧な初期設定と言える。
2. 「単一モデルの限界」を統計学で克服する
仮に、1つの予測モデルが単体で持つ予測精度(凶悪犯罪を正しく予知できる確率)が「80%(0.8)」だとしよう。
これでも十分に高性能だが、治安維持の国家インフラとしては「20%の確率で冤罪や見落としが発生する」ことになり、信頼性は不十分だ。
しかし、「互いに独立した(異なる特徴量を学習した)精度80%のモデル」を3つ並べて多数決(2つ以上が一致したら出力)させるとどうなるか。統計学(二項分布)の計算を用いると、システム全体の予測精度は以下のように跳ね上がる。
- 3つのモデルすべてが的中する確率: $0.8 \times 0.8 \times 0.8 = 0.512$
- いずれか2つのモデルが的中する確率: $3 \times (0.8 \times 0.8 \times 0.2) = 0.384$
- システム全体の統合精度(多数決の的中率): $0.512 + 0.384 = 89.6\%$
単体では80%の性能しか出せないモデルでも、3つをアンサンブル(多数決)にするだけで、システム全体の精度は約90%までブーストされるのだ。
劇中でアーサーとダシールが常に双子(よく似た双方向のデータソース)として描かれ、アガサがより深い洞察(異なるバイアスを持たないインプット)を持つように、それぞれが「異なる視点からデータを評価するインフラ」として機能しているからこそ、プレクリム・システムは驚異的な再現性を維持できている。
現代の予測AIも、全く同じ思想で動いている。単一のアルゴリズムの限界を、統計学の力で突破する——これこそが、映画『マイノリティ・リポート』の犯罪予測システムから現代のエンジニアが学ぶべき、最大の実装モデルなのだ。
現代のAI技術で挑む「プレクリム・システム」実装へのアプローチ
2054年のテクノロジーである「プレクリム・システム」を、2026年現在のAI技術(LLM、マルチモーダル、時系列予測、マルチエージェント)を総動員して再現する場合、どのようなシステムアーキテクチャになるだろうか。
結論から言えば、現代の技術による「再現度は45%」。
点数が低く見えるかもしれないが、「データ予測」の側面においては驚くべき精度といえる。
しかし、劇中のような「特定の個人の犯行を100%確定させて事前に逮捕する」というレベルには到達できない。そのアーキテクチャとボトルネックを詳細を解説しよう。
1. 現代版プレクリムのシステムアーキテクチャ
もし今、このシステムを実装するなら、以下の3つのAIエンジンを「アンサンブル(統合)」させる設計になる。
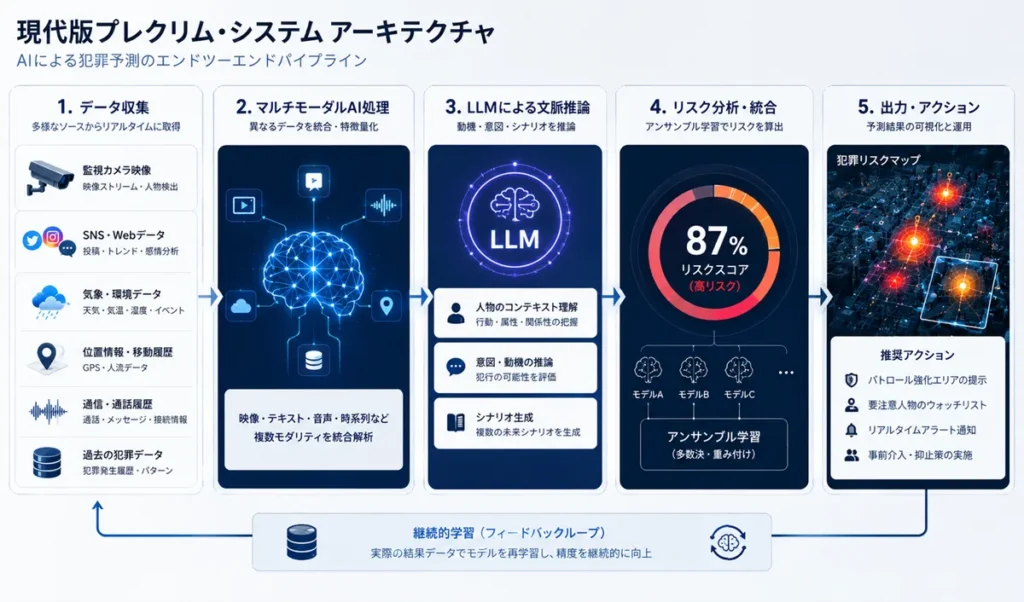
- ① 時系列データ×地理空間AI(「いつ、どこで」の予測)過去の犯罪統計、天気、気温、イベントスケジュール、さらにはSNSのトレンドや経済指標をインプットとし、時空間点過程(Spatio-Temporal Point Process)モデルやグラフニューラルネットワーク(GNN)を用いて、数時間以内に犯罪が発生する「ホットスポット」を高精度で特定する。
- ② マルチモーダルAI×異常行動解析(「誰が、何を」の検知)街頭の監視カメラや高感度マイクと直結したエッジAIだ。人間の骨格動きから「焦り」「敵意」などの不審行動を検出するポーズエスティメーションや、足音、怒鳴り声の音響解析を組み合わせる。
- ③ 超巨大LLMによる「犯罪動機・コンテキスト」の推論ターゲットの通信履歴(メール、チャット、検索履歴)から、LLM(大規模言語モデル)の高度なセマンティック解析を用いて「犯行の決意や動機」が閾値を超えた瞬間をリアルタイムでスコアリングする。
2. なぜ「再現度45%」なのか?技術的な3大ボトルネック
データ予測や異常検知の技術がこれだけ進化しているにもかかわらず、劇中のシステムに届かないのには、現代科学が直面している決定的な限界があるからだ。

- 限界①:カオス理論と「バタフライ効果」の壁人間の行動や社会システムは、初期値のわずかな違いで結果が激変する不確実性の塊だ。気象予測が1ヶ月先をピンポイントで当てられないのと同じで、AIが「明日、AさんがBさんを刺す」と100%の精度で予測することは、計算複雑性の観点から不可能である。
- 限界②:マルチモーダルな「映像データの言語化」におけるブラックボックスプリコグ(予言者)たちが出力する「断片的なイメージ映像」をAIに学習・解析させることは現代でも可能(動画生成の逆算)だが、なぜAIがその結論(犯行の瞬間)に至ったのかという「説明可能性(XAI)」が著しく低い。これでは「事前逮捕」の法的根拠にできない。
- 限界③:自己成就予言(Self-fulfilling prophecy)によるデータの汚染AIが「ここで犯罪が起きる」と予測して警察官を派遣すると、犯罪が未然に防がれる。すると、AIのデータ上は「犯罪が起きなかった(予測が外れた)」という不正解データとしてカウントされてしまい、学習モデルが自己崩壊していくというパラドックス(反実仮想の評価難易度)を現代数学はまだ完全には解決できていない。
技術的結論:
現代のAIができるのは「犯罪が発生する確率の高いエリアと時間を絞り込み、パトロールを強化する(Predictive Policing:予測警察)」という確率論的なアプローチまでだ。劇中のように「確定した未来」として個人の自由を奪うには、決定論的な量子コンピューティングや、人間の脳細胞(バイオコンピュータ)とダイレクトに同期するような、まだ見ぬブレイクスルーが必要になる。
プレクリム再現度の内訳スコア(合計45点 / 100点)
現代のテクノロジーを100点満点で評価すると、以下の「3つの掛け算(または足し算)」で45点になる。
| 評価項目(プレクリムのコア機能) | 現代技術での達成度 | スコア |
| 1. 犯罪の「時空間」予測(いつ、どこで) | 90%(ほぼ完成) | 25点 / 25点 |
| 2. 犯行の「コンテキスト」特定(誰が、何を) | 60%(限定的) | 15点 / 25点 |
| 3. 未来の「決定論的」確定(100%の事前逮捕) | 0%(絶対不可能) | 0点 / 50点 |
| 4. 未構造化データの映像化技術(脳内ビジュアル化) | 50%(研究段階) | 5点 / 10点 |
| 合計スコア | — | 45% |
現代の犯罪時空間予測を支える3つのコア技術

1. 「自己興奮型点過程(ホークス過程)」モデル
現代の予測AI(PredPolなど)の心臓部にあるのは、実は「地震の余震予測」の数理モデル(ホークス過程:Hawkes Process)。
犯罪には「一度発生すると、その周辺で短期間に連鎖しやすい(余震と同じ)」という強い特性(自己興奮性)がある。例えば、ある家が空き巣に狙われたら、その数日以内に近隣の家も被害に遭う確率が跳ね上がるんだ。
AIはこの「本震と余震」の発生確率を時間・空間の両面からリアルタイムに計算し、次にエネルギー(犯罪リスク)が爆発しそうな500フィート四方(約150メートル四方)のボックスを地図上にピンポイントで弾き出す。
2. 環境犯罪学×グラフニューラルネットワーク(GNN)
AIは単に過去のピンを眺めているだけじゃない。「環境犯罪学」の知見を学習している。
- 空間データ: 居酒屋の数、街灯の密度、防犯カメラの位置、駅からの距離、道路の形状(行き止まりが多いかなど)
- 動的データ: 現在の天気、気温(気温が上がると暴行事件が増える統計がある)、地域のイベントスケジュール
これらの複雑に絡み合う都市データを「グラフ構造(ネットワーク)」としてAI(GNN)に食わせることで、「雨の日の金曜の夜、特定の路地裏でひったくりが起きる確率」を、人間には不可能な次元で予測が可能となる。
3. 日本国内でのリアルな実装事例(達成度90%の裏付け)
海外の話だけじゃなく、日本でも警察庁や各県警がすでに動いている。
実際にこれらを導入した地域では、「街頭犯罪(ひったくりや車上荒らし)の件数が数十%減少した」という具体的なエビデンス(成果)が次々と出ている。
参考情報:
神奈川県警の「高度分析システム」や、京都府警が運用していた「予測型犯罪防御システム(YOKOGAWA)」などが有名だ。過去10年分以上の「職質データ」「認知件数」「110番入電履歴」をAIが学習し、パトロールすべきルートを最適化している。
URL:https://www.npa.go.jp/keidai/resources/kikan/seisaku/seisaku/27-1-2-386.pdf
3. 世界に目を向けると…(配点25点の元祖)
海外、特にアメリカのロサンゼルス市警察(LAPD)やアトランタ市警察が導入した「PredPol(プレドポル)」という予測AIソフトは、導入からわずか数ヶ月で財産犯罪を15〜20%減少させたという実績を持ち、これが世界的なトレンドの火付け役になっている。
参考情報:
PredPolのアルゴリズムは、UCLA(カリフォルニア大学ロサンゼルス校)の人類学教授ジェフリー・ブランティンガム(P. Jeffrey Brantingham)氏らの研究チームと、LAPD(ロサンゼルス市警察)の副警視監であったショーン・マリノフスキー(Sean Malinowski)氏らの共同研究によって開発。 地震の余震モデル(ホークス過程)を犯罪予測に適用した核心的な論文が以下になる。
- UCLAによる公式発表:Predictive policing substantially reduces crime in Los Angeles during months-long test (UCLA Newsroom)
- 内容: UCLA主導のチームがLAPDの3つの管区で21ヶ月間にわたり実証実験(ランダム化比較試験)を行った結果、従来の犯罪アナリストの手手法に比べて約2倍の精度で犯罪を予測し、大幅な犯罪率の低下と年間約900万ドルの社会的コスト削減を実現したという研究報告だ。
しかしながら、このPredPol(現在はGeoliticaという名前にリブランディングされている)だが、実は2020年頃にLAPDでの運用が停止されている。
理由は「予算削減」や、AIが過去の偏った逮捕データを学習した結果、特定の有色人種コミュニティばかりを過剰にパトロールさせてしまう「人種バイアスの再生産」という倫理的・技術的な欠陥がデータジャーナリズム(The Markupなどの調査)によって暴かれたため。
【マイノリティ・リポート(少数意見)の哲学が示す、AI時代の生存戦略】
プレクリム・システム(犯罪予測)の崩壊、そして現実世界における「PredPol」の運用停止。
これら2つの史実が現代の俺たちに突きつける最大の教訓は、「統計的な正しさ(多数決)が、常に倫理的な正解とは限らない」という不都合な真実だ。
劇中において、3人のモデル(プリコグ)のうち、アガサだけが他の2人と異なる未来を予測した。これこそが、システムのバグとして隠蔽されていた「マイノリティ・リポート(少数意見)」である。
システム運用側は、予測精度を高めるためのアンサンブル学習(多数決)において、この「1人の異論」をノイズ(外れ値)として切り捨て、100%の安定稼働という神話を維持しようとした。
しかし、その切り捨てられたノイズの中にこそ、「人間が自由意志で未来を変える可能性」という最も尊いデータがある。
現代のAI開発においても、これと全く同じ構造の罠(バイアス)が存在している。

1. 多数決AIがもたらす「エコーチェンバー」と「差別の再生産」
現代のLLMや予測モデルは、過去の膨大な「マジョリティのデータ」を学習して最適化されている。そのため、効率や確率を最優先すると、システムは自動的に「過去と同じパターンの未来」を出力し続けることになる。
もし、現実の予測警察AIが「過去に逮捕者が多かった地域」ばかりを重点的にパトロールさせれば、そこでの検挙率が上がり、AIは「ほら、私の予測が当たったでしょう」と錯覚する(過学習のループ)。
これが、PredPolが直面した人種バイアスの再生産の正体だ。
多数派のデータだけで構築された「完璧な予測システム」は、社会の多様性や、人間が過去の過ちを反省して行動を変える「オルタナティブな未来(別の可能性)」を最初から計算から排除してしまう危険性を持っている。
2. エンジニアが持つべき「マイノリティ・リポート」の視点
だからこそ、AI時代を生きるデータサイエンティストやエンジニアは、システムが出した「99%の最適解」を盲信するだけのオペレーターになってはならない。
切り捨てられた1%の「外れ値(アノマリー)」に目を向け、「なぜこのモデルは異なる出力をしたのか?」「データに偏り(バイアス)はないか?」を常に問い続ける、アガサの監視者としての倫理観が必要不可欠になる。





コメント